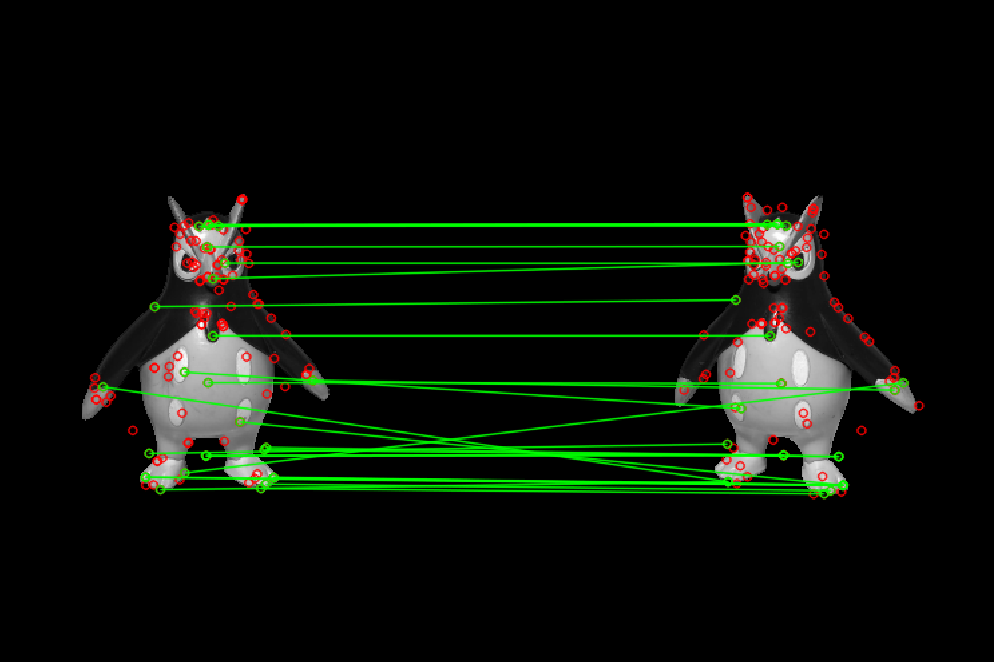
2D_3D Reconstruction
Our goal for this project is to capture a series of images and process them to form a point cloud – a 3D representation of the original object.
Task
Design and developing a computer vision algorithm that takes a series of 2D images to reconstruct a 3D model – photogrammetry.